Все мы знаем, что PHP — интерпретируемый язык. Но что на самом деле происходит с нашим PHP скриптом?
Изначально наш код читается, происходит его разбор и преобразование в так называемые «токены». Это позволяет нашему интерпретатору разбить код на фрагменты, понять где они находятся. Этот процесс называется токенизация или лексирование.
Дальше, имея токены, происходит синтаксический анализ (он также называется parsing), который генерирует абстрактное синтаксическое дерево (Abstract Syntax Tree — AST) для того чтобы было проще понять какие есть операции и какой у них приоритет. На этом этапе приходит анализ тех самых токенов.
Дальше происходит компиляция (преобразование) AST в операционный код (Opcode), который наконец и сможет быть выполнен. Не стоит путать, преобразование происходит не в команды ассемблера (очень низкоуровневые), это именно опкоды для виртуальной машины PHP, в них гораздо больше логики.
Далее, виртуальный движок Zend VM (Virtual Machine) получает список наших Opcode и выполняет их! Вот схема всего процесса.
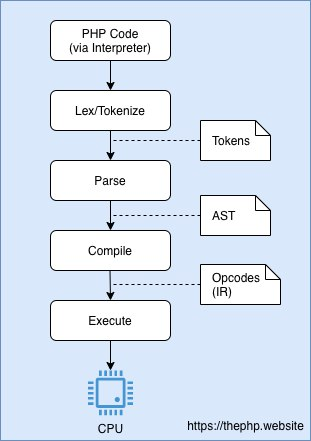
Но после выполнения опкоды немедленно уничтожаются. Возникает вопрос: зачем нам каждый раз токенизирвоать, парсить и компилировать PHP код?
Очень маловероятно, что на production-серверах PHP-код изменится между выполнением нескольких запросов, а значит и Opcode будет точно таким же.
В связи с этим было разработано расширение для кэширования опкодов — Opcache. Его главная задача — единожды скомпилировать каждый PHP-скрипт и закэшировать получившиеся опкоды в общую память, чтобы их мог считать и выполнить каждый рабочий процесс PHP из вашего пула (PHP-FPM). Вот схема с учетом использования Opcache. Расширение Opcache поставляется с PHP.
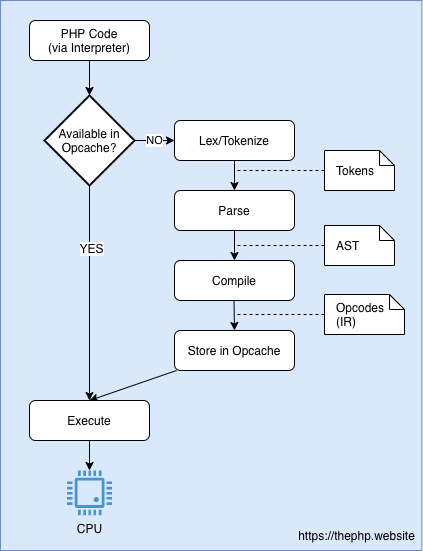
В результате на запуск скрипта уходит как минимум вдвое меньше времени (сильно зависит от самого скрипта). Чем сложнее приложение, тем выше эффективность этой оптимизации.
Спасибо за подробное разъяснение Kirill Sulimovsky